Scraping LinkedIn Topics and Skills Data

Have you ever asked:
- What are the most popular skills among LinkedIn users?
- What are the most popular skills among Microsoft employees?
- Other top tech companies? (Google, Amazon, Facebook, etc...)
- What are the most interconnected skills?
These are questions that LinkedIn does not provide a direct answer to. However, through their "Topics Directory", we should be able to come to these conclusions ourselves!
The Topics Directory seems to be an index over all the different skills that people have put on their profile, alphabetically ordered by skill name. Some pages, like Azure, have very specific metadata about the skill, while others like Azure Active Directory, show up in the directory, but do not have this additional metadata.
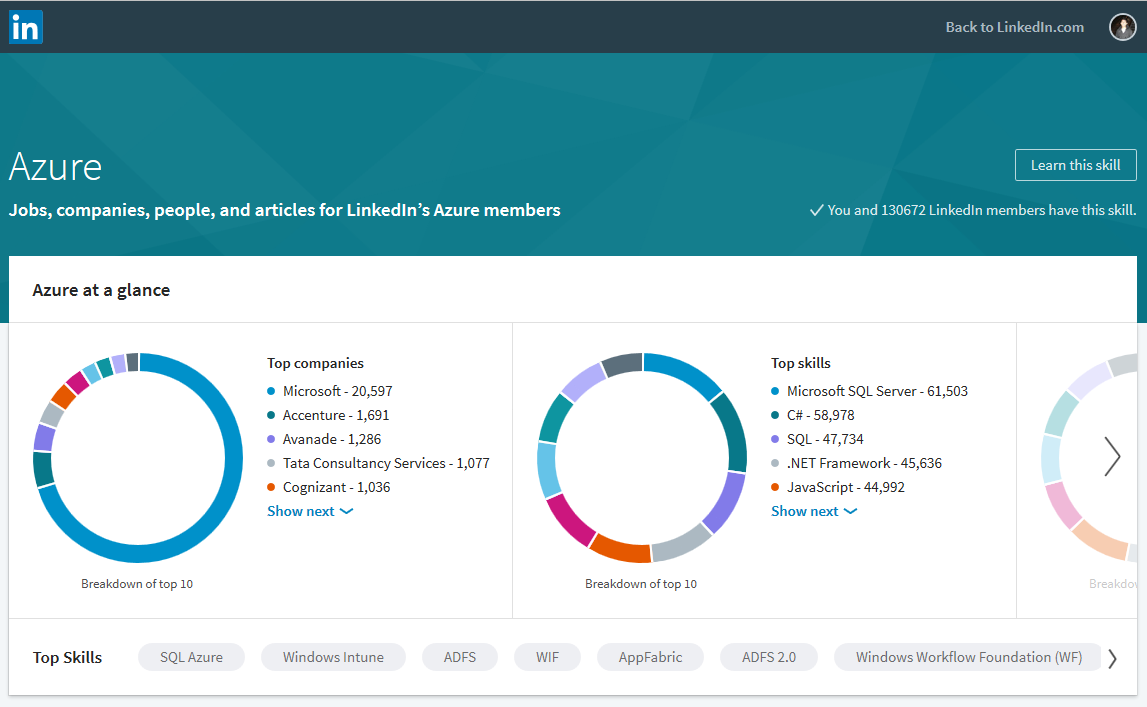
If we look at the additional metadata, you can see that it calls out a number of very interesting data points. It tells you:
- How many people have this skill
- The top 10 companies that have employees who register this skill
- (My guess) The top skills that people have who also have this skill
- (My guess) The top related skills
Now clearly, there is some poor Web Design, in that there are two different sections, both with the same title "Top Skills", but contain different data. We will have to do our own interpretation of what this data exactly means, but nonetheless, the data is all useful.
So how do we start scouring this data to answer the questions I proposed at the start of this post? Well, by scraping it of course, and storing it into our own database. Now, this is not an original idea, but certainly I have not seen anyone collect the level of data which I am interested in. I want to have a copy of all the data points above for each topic, all in a single list!
So let's do it!
Of course we will be using Python + Beautiful Soup + Requests. You can find the latest version of my LinkedIn scraper on my GitHub. Here, I will only be looking at the main function, which describes the logic of my code, not the specific functions which actually does the scraping. You can find that on my GitHub.
from bs4 import BeautifulSoup
import requests
import string
import re
import json
# ...
# sub-functions removed, check GitHub for full source
# ...
def main():
letters = list(string.ascii_lowercase)
letters.append('more')
base_url = "https://www.linkedin.com/directory/topics-"
for letter in letters:
letter_url = base_url + letter + "/"
content = get_content(letter_url)
for con in content:
if letter == 'y' or letter == 'z':
sub_content = content
else:
letter_page_url = con.find("a")
print(letter_page_url)
if letter_page_url.has_attr('href'):
sub_content = get_content(letter_page_url['href'])
else:
sub_content = None
for sub_con in sub_content:
topic_url = sub_con.find("a")
topic = scrape_data(topic_url)
create_json(topic)
if letter == 'y' or letter == 'z':
break
To scrape this site, we are basically figuring out the pattern which generates these pages. LinkedIn organizes these topics first by letter:
https://www.linkedin.com/directory/topics-{letter}/
Then on each "letter page", they group the topics by alphabetical order, in groups:
https://www.linkedin.com/directory/topics-{letter}-{number}/
Finally, if you navigate to the specific topic, you will get the final page with data:
https://www.linkedin.com/topic/{topic}
There are a few exceptions to this pattern, which added complexity to the scraper. Basically the letters Y and Z do not have enough topics to be able to put them in groups, which means instead of navigating 3 pages deep to get the data, we need to navigate only 2 pages deep. You can see I handle this situation in my scraper. Other than that, once I get the data off the page, I put it into a JSON file for later usage!
One thing to note, but that I will not go into detail here about is that LinkedIn actually blocks scrapers in general, by creating a 999 response when you try to get data using a bot. If you want to run this script, you will have to overcome this. If you look online, people mention that you might need to update the user-agent passed in the headers of the web requests, but this did not work for me. I might go into detail about this during another post.
Results
So, let's look at some of the data. I can import the JSON as an array of dictionaries in Python, and then try and write some queries to get data from it. I am not claiming to write the best or most efficient queries, but hopefully they will get the correct data.
Loading the data:
with open(r'C:\Users\shawn\Documents\GitHubVisualStudio\LinkedIn-Topic-Skill-Analysis\results\linkedin_topics_7-23-17.json') as data_file:
data = json.load(data_file)
How many topics are there total?
len(data)
33188
What are the most popular overall topics/skills?
ordered_by_count = sorted(data, key=lambda k: k['count'] if isinstance(k['count'],int) else 0, reverse=True)
for skill in ordered_by_count[:20]:
print(skill['name'])
Management - 69725749 Microsoft - 55910552 Office - 46632581 Microsoft Office - 45351678 Planning - 34397412 Microsoft Excel - 32966966 Leadership - 31017503 Customer Service - 30810924 Leadership Management - 25854094 Word - 25793371 Project - 25766790 Project+ - 25766790 Microsoft Word - 25567902 Business - 25374740 Customer Management - 24946045 Management Development - 24207445 Development Management - 24207409 Project Management - 23922491 Marketing - 23047665 Customer Service Management - 22856920
What are the top Skills?
company = 'Microsoft'
company_skills = []
for skill in ordered_by_count:
if skill['companies'] is not None:
if company in skill['companies']:
company_skills.append(skill)
order_by_company = sorted(company_skills, key=lambda k: k['companies'][company], reverse=True)
for skill in order_by_company[:20]:
print(skill['name'], "-", skill['companies'][company])
Microsoft
Cloud - 74817 Cloud Computing - 74817 Cloud-Computing - 74817 Cloud Services - 74817 Management - 73123 Management Skills - 73123 Multi-Unit Management - 73123 Enterprise - 54516 Enterprise Software - 54516 Software Development - 53201 Project Management - 52083 Project Management Skills - 52083 PMP - 52083 PMI - 52083 Strategy - 43983 SaaS - 41450 Software as a Service - 41450 Program Management - 40749 Business Intelligence - 39291 C# - 39158
Google
Java - 23225 Strategy - 22235 Marketing - 21672 Data-driven Marketing - 21672 Python - 20788 Software Development - 20406 C++ - 20199 Social Media - 20082 Social Networks - 20082 Digital Marketing - 19942 Online Advertising - 19922 Marketing Strategy - 16882 Linux - 16272 JavaScript - 14567 JavaScript Frameworks - 14567 C - 14460 C Programming - 14460 Online Marketing - 13925 Online-Marketing - 13925 Social Media Marketing - 12931
Amazon
Leadership - 44329 Leadership Skills - 44329 Microsoft Office - 42713 Office for Mac - 42713 Customer Service - 36176 Microsoft Excel - 33403 Java - 25609 Word - 23314 Microsoft Word - 23314 PowerPoint - 22318 Microsoft PowerPoint - 22318 Social Media - 22110 Social Networks - 22110 C++ - 19619 Training - 19250 Marketing - 18826 Data-driven Marketing - 18826 Software Development - 18521 Public Speaking - 17366 C - 16813
Facebook
Digital Marketing - 4973 Online Advertising - 4334 Digital Strategy - 3399 Online Marketing - 3012 Online-Marketing - 3012 Facebook - 2883 Algorithms - 2881 Mobile Marketing - 2163 Machine Learning - 2103 Distributed Systems - 2033 User Experience - 1971 UX - 1971 Web Analytics - 1682 SEM - 1626 Computer Science - 1440 Google Analytics - 1261 Adwords - 1093 Google AdWords - 1093 Scalability - 1057 Mobile Advertising - 919
What are the top interconnected skills?
skill_count = {}
for topic in data:
if topic['skills'] is not None:
for top_skill in topic['skills']:
if top_skill not in skill_count:
skill_count[top_skill] = 1
else:
skill_count[top_skill] += 1
if topic['topSkills'] is not None:
for top_skill in topic['topSkills']:
if top_skill not in skill_count:
skill_count[top_skill] = 1
else:
skill_count[top_skill] += 1
for skill in sorted(skill_count, key=skill_count.get, reverse = True)[:20]:
print(skill, "-", skill_count[skill])
Microsoft Office - 11081 Management - 8845 Customer Service - 7010 Project Management - 6902 Microsoft Excel - 4884 Leadership - 4682 Social Media - 3883 Research - 3798 Public Speaking - 3243 Marketing - 2644 Microsoft Word - 2426 Sales - 2335 SQL - 2322 Engineering - 2300 Business Development - 2071 Strategic Planning - 1879 Java - 1792 Adobe Photoshop - 1555 JavaScript - 1488 Microsoft PowerPoint - 1483
There is so much more we can do with this data, and I do have plans! I just can't talk about them here. In a related note, I am super excited for the Microsoft Hackathon happening this next week. I will be using these tools, and hopefully more to accomplish an awesome project. Maybe more to share here in the future!